Les spécialistes notent que les techniques de réseaux et d’administration servent autant les ingénieurs que les équipes marketing, dès qu’un site promet un avantage instantané. À titre d’exemple, un casino bonus sans depot illustre à merveille comment latence, sécurité et intégrité des données décident de la confiance des utilisateurs. Entre algorithmes, temps exact et mises en cache, tout doit vibrer à l’unisson.
Pourquoi la synchronisation du temps conditionne une promotion
Une promotion ne vaut que si l’horloge du système est exacte et cohérente partout. Pour un service d’avantages, le temps est une dépendance critique et discrète. Selon l’expérience des collègues, sans une référence temporelle fiable, les expirations d’offres, les limites quotidiennes et les journaux perdent leur valeur probante, et c’est la porte ouverte aux réclamations. Concrètement, le protocole de temps réseau et la discipline d’horloge au niveau des serveurs d’applications, des bases de données et des mandataires jouent la partition commune qui évite les fausses dissonances entre « déjà offert » et « encore disponible ». Entre-temps, les équipes d’exploitation rappellent que l’horodatage gouverne aussi la détection d’abus, car une règle de fréquence dépend d’une mesure de secondes strictement partagée. Enfin, la chaîne entière — du conteneur à l’équilibreur, du journal au tableau de bord — doit vivre dans le même fuseau logique, sous peine de diagnostics trompeurs et de réconciliations interminables.
Les spécialistes recommandent au minimum deux sources de temps indépendantes, une interne et une externe, avec bascule automatique en cas d’écart détecté, et des seuils d’alerte clairs pour chaque hôte critique. Ils insistent aussi sur la vérification continue de la dérive et sur l’audit des déploiements, car une image de serveur mal configurée suffit à désaccorder un cluster entier, parfois sans symptôme visible avant la première vague d’utilisateurs. D’ailleurs, dans le cadre d’offres limitées à une journée civile, la définition même de « jour » doit être unifiée, que l’infrastructure soit étalée sur plusieurs régions ou non. Sans oublier l’impact juridique : l’horodatage apposé sur l’acceptation de conditions particulières est un élément de preuve, et sa fiabilité repose d’abord sur l’alignement temporel. Par expérience, les spécialistes préfèrent des vérifications canari automatisées qui comparent, à intervalles réguliers, l’horloge applicative et la référence de l’instrumentation.
Pour aider les équipes, un guide détaillé sur le protocole de temps réseau et les bonnes pratiques d’orchestration réduit les surprises lors des montées en charge. Par ailleurs, un simple service témoin qui renvoie le temps de référence et l’écart perçu par chaque nœud offre une visibilité apaisante, surtout pendant les pics. Honnêtement, personne n’a envie de débattre à minuit si telle opération a expiré à 23:59:58 ou à 00:00:03, quand une politique claire et une horloge disciplinée tranchent en une ligne. Et pourtant, cela reste l’un des angles morts les plus fréquents dans les plateformes d’avantages. Cela vaut la peine d’y revenir souvent, avec rigueur et pédagogie.
Tableau de référence pratique ci‑dessous, utile pour calibrer les choix initiaux et les contrôles en production :
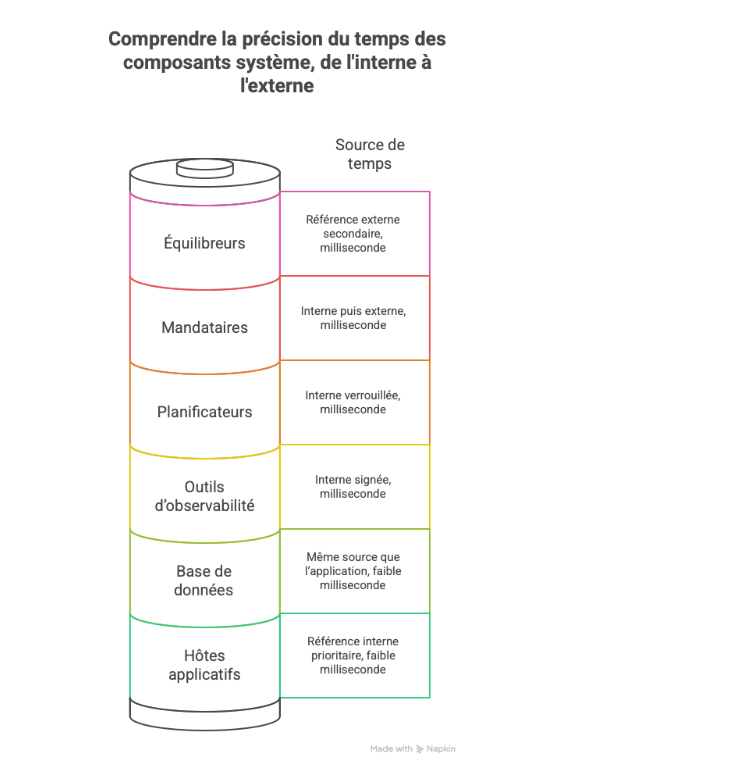
| Composant | Source de temps | Précision attendue | Contrôle d’écart | Action de remédiation | Impact si défaillant |
| Hôtes applicatifs | Référence interne prioritaire | Faible milliseconde | Alerte à seuil | Resynchronisation forcée | Limites horaires incohérentes |
| Base de données | Même source que l’application | Faible milliseconde | Comparaison régulière | Migration contrôlée | Transactions datées hors séquence |
| Équilibreurs | Référence externe secondaire | Milliseconde | Auto-bascule | Reprise automatique | Journaux non corrélables |
| Mandataires | Interne puis externe | Milliseconde | Vérification au démarrage | Refus de démarrer | Cookies et jetons invalides |
| Outils d’observabilité | Interne signée | Milliseconde | Comparaison tripartite | Réalignement | Alertes fantômes |
| Planificateurs | Interne verrouillée | Milliseconde | Tests de cohérence | Pause contrôlée | Tâches déclenchées à contre‑temps |
Concevoir une architecture de service de bonus robuste
Un système d’avantages solide sépare clairement attribution, éligibilité et comptabilisation. Cette séparation réduit la complexité et évite les effets de bord. Dans la pratique, il est conseillé de découper le domaine en services bien bornés : un service d’éligibilité calcule si l’utilisateur a droit à l’avantage, un service d’attribution émet une décision idempotente et un service de solde enregistre l’impact financier. Les spécialistes insistent sur l’isolement transactionnel et sur la règle d’or suivante : ce qui change le moins doit décider ce qui change le plus, autrement dit les règles signées et leur version guident l’exécution dynamique. Par ailleurs, la résistance aux doubles clics et aux rafraîchissements frénétiques se gagne via des jetons uniques et des opérations idempotentes, sujet détaillé dans opérations idempotentes. Enfin, une file de messages tempère les à‑coups de trafic et garantit que chaque décision est traitée exactement une fois, ou reconduite de façon contrôlée.
Les équipes IT constatent que la gouvernance de la vérité est un défi récurrent : où vit la règle qui dit « une fois par personne » ou « une fois par appareil » et comment évolue‑t‑elle sans casser la compatibilité des décisions passées. La bonne pratique consiste à versionner la politique, à la stocker séparément du code, et à signer sa publication pour qu’une relecture ultérieure puisse expliquer « pourquoi » telle décision fut prise. Entre autres, l’outil de simulation en amont des mises en production protège contre les effets inattendus quand un seuil ou une condition est ajusté. D’ailleurs, cette discipline allège le support, car les réponses cessent d’être opinions pour redevenir des faits reconstruits à partir de règles stables et datées.
Du point de vue du trafic, la façade doit accepter des pointes féroces, par exemple lors d’une campagne relayée par un partenaire populaire. Un tampon côté mandataire inverse, une stratégie de limitation de débit en amont et, si nécessaire, un mode de dégradation gracieuse permettent de préserver la cohérence des décisions. Selon l’expérience des collègues, il vaut mieux servir une file d’attente explicite avec position approximative qu’un simple échec silencieux, car la perception d’équité pèse autant que la rapidité pure. Et pourtant, la tentation demeure de noyer la demande dans la capacité brute, ce qui coûte souvent plus cher et ne protège pas contre les effets de timonerie au niveau des bases de données.
Pour ancrer ces conseils, voici une table d’architecture minimale et ses responsabilités, utile lors des ateliers de cadrage :
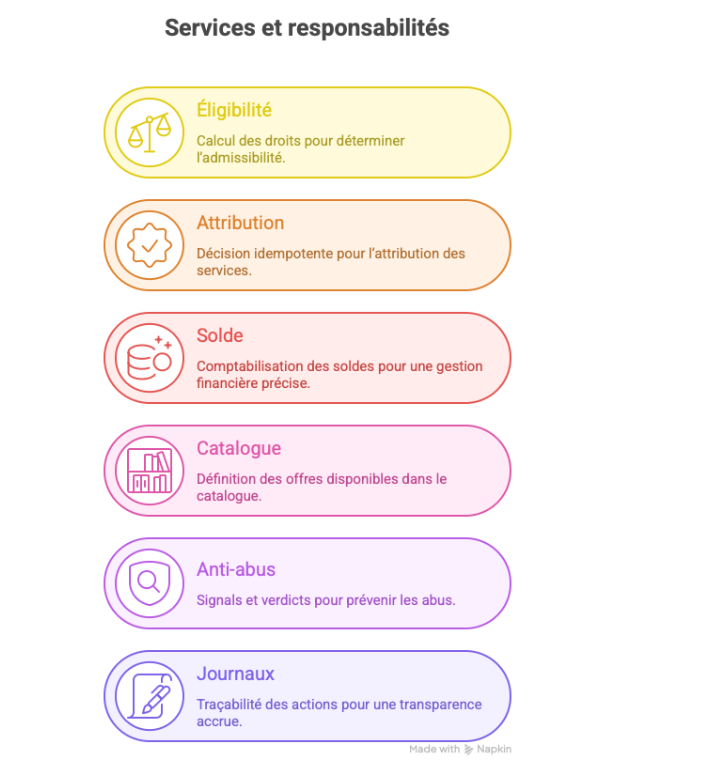
| Service | Responsabilité | Données clés | Contrats d’interface | État | Échecs tolérés |
| Éligibilité | Calcul des droits | Règles versionnées | Décision/raison | Sans état | Relançable |
| Attribution | Décision idempotente | Jeton unique | Attribue/écrit | État transitoire | Relecture |
| Solde | Comptabilisation | Mouvements | Crédit/débit | État durable | Transaction |
| Catalogue | Définition d’offres | Versions | Lire/consulter | État durable | Cache |
| Anti‑abus | Signals et verdicts | Empreintes | Score | État léger | Dégradé |
| Journaux | Traçabilité | Événements | Écrire/chercher | Froid | File |
Limiter la fraude sans dégrader l’expérience
La meilleure lutte contre l’abus est progressive, explicable et mesurée. Une défense efficace refuse peu, mais refuse juste. Les spécialistes recommandent d’agréger plusieurs signaux faibles plutôt que de se reposer sur un critère brutal, car l’erreur coûteuse n’est pas seulement de laisser passer un abus, c’est aussi de refuser à tort un client légitime. Selon la pratique, l’empilement de contraintes légères — rythme, cohérence d’empreinte de navigateur, réputation d’adresse, vérification d’identité proportionnée — fournit une barrière robuste sans friction excessive. À cela s’ajoutent les règles de cohérence métier : un avantage non transférable ne peut pas apparaître sur deux comptes dans la même fenêtre de temps, et chaque décision doit s’appuyer sur un journal horodaté prêt à être consulté par le support. Et, honnêtement, il faut accepter qu’une petite fraction d’abus résiduel coûte moins cher qu’une muraille qui fâche les bons usagers.
Dans ce registre, une approche par paliers est souvent payante : d’abord ralentir, ensuite demander une preuve supplémentaire, enfin bloquer quand l’évidence dépasse un seuil explicite. Les collègues rappellent qu’un blocage sans voie de recours transforme parfois un ambassadeur en détracteur, alors qu’une simple vérification d’identité à froid apaise les deux parties. Entre‑temps, des mécanismes de liens à usage unique et de fenêtres temporelles courtes réduisent l’intérêt des scripts automatisés, surtout si les jetons expirent vite et sont liés à des éléments stables côté serveur. La proportionnalité reste la boussole, et la capacité à expliquer un refus en une phrase lisible est un indicateur de maturité.
Les équipes en charge de l’infrastructure réseau rappellent que la géodistribution des nœuds peut aider à détecter des comportements improbables, comme des connexions successives distantes en un clin d’œil. Toutefois, la géolocalisation n’est pas une preuve, seulement un indice à combiner avec d’autres traces. Par ailleurs, les spécialistes conseillent de publier une page transparente sur les critères généraux d’éligibilité, afin d’éduquer les utilisateurs et d’éviter les tentatives involontaires d’abus. Une politique claire diminue la charge du support et, d’ailleurs, renforce la crédibilité globale du programme d’avantages.
Repère utile pour prioriser les mesures, avec coûts et bénéfices :
| Signal | Abus visé | Coût utilisateur | Coût technique | Robustesse | Explicabilité |
| Rythme de requêtes | Scripts rapides | Faible | Faible | Bonne | Excellente |
| Empreinte navigateur | Multiples comptes | Moyen | Moyen | Variable | Moyenne |
| Réputation d’adresse | Proxys abusifs | Faible | Moyen | Bonne | Bonne |
| Preuve d’humanité | Automatisation | Moyen | Faible | Bonne | Moyenne |
| Vérification d’identité | Usurpation | Élevé | Élevé | Très bonne | Bonne |
| Jetons à usage unique | Réutilisation | Faible | Moyen | Très bonne | Excellente |
Résilience réseau, noms de domaine et mise en cache soignée
Une résolution de nom fiable et une mise en cache disciplinée protègent l’expérience. Un réglage mal pensé peut briser une promotion à lui seul. Les spécialistes rappellent que le système de noms de domaine et les durées de vie associées sont des leviers délicats : trop longues, elles répandent une erreur partout ; trop courtes, elles épuisent l’infrastructure en requêtes. En pratique, l’équilibrage entre plusieurs adresses doit rester masqué par une politique de cache homogène, et la bascule d’urgence passer par des entrées pré‑préparées et bien documentées. Entre autres, un registre interne des dépendances critiques — noms, certificats, chaînes de confiance — raccourcit la nuit quand quelque chose déraille. Et pourtant, cette cartographie manque souvent, jusqu’au jour où un certificat arrive à expiration sur un nœud oublié.
La mise en cache applicative mérite aussi des règles précises : quels éléments du catalogue d’offres peuvent être mis en mémoire et pendant combien de temps, avec quelle stratégie d’invalidation, et comment forcer la fraîcheur lors d’un lancement. Les collègues conseillent une approche par clés dérivées, avec suffixes de version, afin d’éviter les collisions et les résidus de versions précédentes. Par ailleurs, l’équipe peut prévoir une stratégie de « réchauffage » avant une campagne, en sollicitant prudemment les nœuds pour que les chemins critiques soient déjà en mémoire quand la foule arrive. Cette garde‑robe de cache, si l’on ose dire, évite les coups de froid.
Du point de vue diagnostic, une page technique observant le parcours de résolution — vue nom, application, base de données de sessions — est un outil précieux pour le support avancé. Nous renvoyons, pour approfondir, au dossier sur le système de noms de domaine et aux notes sur la cohérence de cache côté client et côté serveur. Une fois ces fondations stables, l’équipe peut se concentrer sur l’essentiel : rendre la décision rapide, juste et explicable. Les spécialistes soulignent que l’élégance d’une architecture se voit souvent lorsqu’elle échoue, pas quand elle triomphe.
Enfin, les chemins critiques doivent rester courts, avec le moins de sauts possible entre le point d’entrée et le service d’attribution. Une simple règle aide : ce qui est décision doit être proche, ce qui est décor peut voyager plus loin. D’ailleurs, les images et modules non essentiels profitent d’une diffusion de contenu, alors que la décision d’attribution mérite une proximité maximale avec les données d’éligibilité. Ce compromis, encore et toujours, protège la réactivité quand le public afflue.
Sécuriser l’échange : chiffrement, certificats et barrières
La confidentialité perçue et réelle conditionne l’adhésion à une offre. Le chiffrement fort et la gestion stricte des certificats ne sont pas négociables. Les spécialistes recommandent une terminaison chiffrée au niveau du mandataire inverse, des suites cryptographiques modernes et des renouvellements de certificats automatisés avec surveillance en double. Par expérience, une politique stricte d’en‑têtes côté navigateur et une séparation des secrets garantissent qu’un incident local ne se propage pas. Entre autres, la rotation fréquente des cookies de session et la signature des jetons d’attribution limitent l’impact d’une fuite ponctuelle. Et pourtant, l’excès d’entropie mal gérée peut aussi créer des séances fantômes et frustrer l’utilisateur, d’où la nécessité d’un équilibre attentif.
Il est préférable d’encapsuler les appels entre services dans des canaux chiffrés, y compris à l’intérieur du réseau privé, car la frontière n’est plus ce qu’elle était. La gestion des accès au moindre privilège, la séparation des rôles et la vérification indépendante des politiques évitent les abus par mégarde. Les collègues aiment rappeler que l’audit technique doit pouvoir rejouer une décision à partir des journaux, sans jamais exposer de données sensibles, ce qui conduit souvent à des formats d’événements bien pensés. Un registre central pour la configuration du mandataire inverse et des politiques d’en‑têtes réduit les divergences entre environnements et facilite l’investigation.
Du côté navigateur, une politique stricte d’isolation des origines, d’usage parcimonieux du stockage local et de stratégies de protection contre l’injection réduit les surfaces d’attaque. Les formulaires d’acceptation doivent inclure des jetons anti‑rejeu, valables sur une courte fenêtre, associés à une empreinte d’environnement pour limiter l’ascenseur à récompenses. À cet égard, la prévention compte plus que la détection tardive, et la pédagogie auprès des équipes frontales comme des équipes d’arrière‑plan fait gagner de longues nuits de réparation. Entre‑temps, un manuel de réponses d’incident réduit le délai entre suspicion et action, en listant qui alerter et comment geler prudemment les décisions sans pénaliser indûment les usagers légitimes.
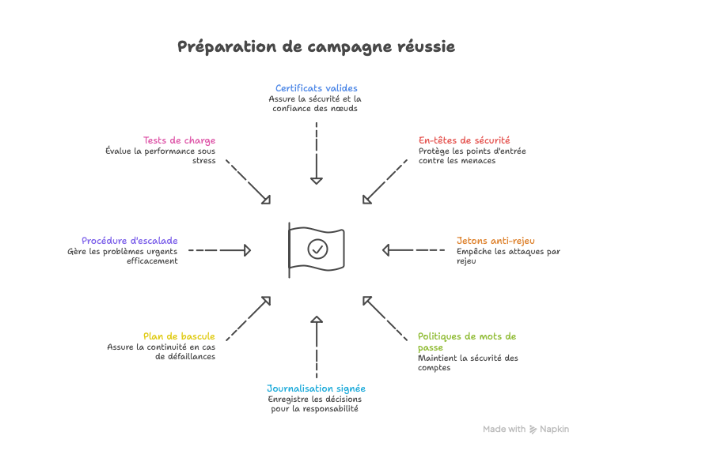
Pour mémoire, une liste de contrôles à exécuter avant chaque campagne importante aide à éviter les oublis :
- Certificats valides sur tous les nœuds exposés, avec renouvellement automatique vérifié
- En‑têtes de sécurité actifs et testés sur l’ensemble des points d’entrée
- Jetons anti‑rejeu fonctionnels et expirations contrôlées
- Politiques de mots de passe et de verrouillage conformes aux standards internes
- Journalisation signée des décisions d’attribution et d’éligibilité
- Plan de bascule prêt pour les failles de dépendances tierces
- Procédure d’escalade documentée pour l’équipe d’astreinte
- Tests de charge et de dégradation gracieuse exécutés et archivés
Observabilité: métriques, journaux et traces utiles
Ce qui n’est pas mesuré se raconte mal, surtout sous pression. Une observabilité claire sauve des heures lors d’un pic. Les spécialistes recommandent une triade simple : des métriques pour voir la tendance, des journaux pour comprendre les décisions et des traces pour suivre le parcours d’une requête à travers les services. La clé reste la parcimonie : quelques indicateurs bien nommés suffisent à piloter, dès lors que leurs seuils d’alerte sont alignés avec les engagements de service. D’ailleurs, la centralisation des journaux — consultable via centralisation des journaux — permet au support d’expliquer une décision à un usager sans mobiliser un développeur. Entre autres, une corrélation par identifiant de décision rend la recherche presque agréable, ce qui n’est pas si courant la nuit.
Les métriques d’or servent des questions concrètes : combien d’attributions par minute, quel taux de refus et pour quelles raisons agrégées, quelle latence pour le parcours critique, combien de relances dans la file. Les collègues prévoient souvent deux tableaux de bord : l’un pour l’instantané opérationnel, l’autre pour l’analyse post‑campagne. Ce duo évite de surcharger un seul écran de chiffres en compétition. Les alertes doivent parler en phrases : « la latence dépasse la cible depuis cinq minutes » vaut mieux qu’un nombre rouge dont on a oublié la signification.
La traçabilité des décisions exige aussi un schéma d’événements stable : décision pensable, décision prise, décision écrite en base, décision communiquée, avec horodatage synchronisé et empreinte de version de la règle. Ces jalons offrent de l’appui au moment où l’on soupçonne un trou noir, et, honnêtement, rassurent quiconque doit répondre à un message du support. Les ingénieurs, eux, retrouvent rapidement quel maillon a ralenti, ce qui accélère le correctif. Par expérience, ce canevas réduit les disputes et prolonge la patience de tous pendant les orages.
Pour cadrer la mise en place, un tableau synthétique aide à répartir les efforts :
| Signal | Question à laquelle il répond | Seuil d’alerte type | Destinataire | Action immédiate | Action différée |
| Latence parcours critique | Sommes‑nous rapides ? | Au‑delà de la cible 5 min | Exploitation | Dégradation gracieuse | Optimisation |
| Taux de refus | Refusons‑nous trop ? | Écart de x % | Produit | Pause ciblée | Réglage règles |
| Erreurs d’écriture | Perdons‑nous des décisions ? | Au‑delà d’un seuil | Base de données | Basculer | Relecture |
| Épaisseur de file | Rattrapons‑nous ? | Surcroît soudain | Exploitation | Scalabilité | Profilage |
| Écart d’horloge | Sommes‑nous alignés ? | Dépassement léger | Exploitation | Resynchronisation | Audit images |
| Échecs anti‑abus | Sommes‑nous attaqués ? | Hausse brutale | Sécurité | Renforcer | Investigation |
Gestion de la charge, files et algorithmes d’attribution
Un bon algorithme est rapide, stable et juste sous pression. Les files amortissent les chocs sans sacrifier l’équité. Les spécialistes préconisent une attribution déterministe quand le stock est limité, en ordonnant les demandes selon un critère public et simple, par exemple l’instant de réception reconnu par le mandataire. Cette transparence réduit les polémiques et permet au support d’expliquer calmement pourquoi telle demande fut servie et telle autre non. Entre autres, une politique de limitation de débit par identifiant d’utilisateur et par adresse lisse la pointe et stabilise les arrières. Sur ce point, un article dédié détaille l’implémentation de la limitation de débit dans le mandataire et l’application. D’ailleurs, la grâce d’un service se mesure au moment où il dit « pas maintenant » sans rompre le fil de confiance.
Pour éviter les doubles attributions, les opérations d’écriture doivent être idempotentes et portées par des clés naturelles ou dérivées, suffisamment solides pour résister aux relectures en cas de reprise. Une technique appréciée consiste à générer un identifiant de décision à la réception et à le propager jusqu’à la base de données, rendant toute répétition détectable. Selon l’expérience des collègues, l’enchaînement « vérifier l’éligibilité, consommer un jeton unique, écrire la décision, publier l’événement » se prête bien à la reprise en cas de panne à mi‑parcours. Ce canevas réduit le nombre de cas ambigus où l’on hésite entre « déjà accordé » et « encore possible », source classique de frustration.
La gestion de la file elle‑même mérite un soin constant : que faire quand elle grossit, quand elle se vide d’un coup, quand une part de messages échoue systématiquement. Les équipes IT mettent en place des politiques de parcimonie, des aires de quarantaine pour les messages malformés et des tentatives différées avec délai croissant. Tout cela paraît aride, mais c’est précisément ce qui épargne des week‑ends entiers quand la réalité dépasse les scénarios optimistes. Entre‑temps, une visualisation lisible de la file, avec quelques seuils peints en orange plutôt qu’en rouge, garde les nerfs calmes.
Enfin, quand l’algorithme dépend d’un calcul de probabilité — par exemple pour distribuer des avantages aléatoires dans une fenêtre — la transparence exige une source d’aléa vérifiable, documentée et stable. Les spécialistes encouragent l’utilisation de générateurs modernes, avec publication du sel de campagne et contrôle d’équité a posteriori. On sous‑estime combien l’ombre du doute fatigue une communauté, surtout si une poignée d’utilisateurs persuadés de leur malchance chronique montent le ton. Une petite page d’explications mathématiques, rédigée simplement, peut faire des merveilles pour ramener la sérénité.
Conception de la base de données pour les avantages promotionnels
Une base claire, c’est une nuit tranquille. La structure des tables et les contraintes dictent la robustesse. Les spécialistes recommandent une séparation nette entre les définitions d’offres, les décisions d’attribution, les mouvements de solde et les journaux d’événements. La clé naturelle d’attribution combine l’identifiant d’utilisateur, l’identifiant d’offre, la version de règle et l’instant de décision arrondi à une fenêtre, ce qui autorise un rejet idempotent en cas de répétition. Entre autres, des index sur les colonnes de recherche fréquente — par utilisateur, par période, par type d’offre — accélèrent le support et les rapports sans pluie d’analyses coûteuses. D’ailleurs, une table d’audit en écriture seule, immuable, rassure tout le monde lors d’un incident.
Au chapitre des transactions, l’isolation doit être pragmatique : suffisante pour empêcher des doubles écritures, mais pas au point de paralyser la concurrence. Les collègues évitent les verrous trop larges, préférant des contraintes uniques et des essais contrôlés via rattrapage logique. Les opérations critiques s’enveloppent dans des blocs courts, et les validations tardives contrôlent les invariants à peu de frais. Cela paraît presque trop simple, mais c’est précisément cette sobriété qui dure.
La rétention des données, elle, relève autant du droit que de la technique. Les offres expirées et les décisions obsolètes doivent sortir du chemin chaud, sans perdre leur valeur probante. Les spécialistes prônent un archivage périodique, vers une zone de stockage plus froide, avec consultation sécurisée pour les rares cas nécessitant une relecture. Le règlement général sur la protection des données ajoute des exigences d’effacement et d’information que l’architecture doit servir naturellement, plutôt que de bricoler des exceptions douloureuses. Entre‑temps, un dictionnaire de données vivant évite les malentendus lors des audits.
Enfin, documenter la signification de chaque colonne et l’algèbre des états évite les écarts d’interprétation entre l’équipe produit et l’équipe technique. Une décision « accordée » n’est pas une décision « consommée », et ce distinguo doit être clair dans la base, l’interface et les rapports. Les spécialistes partagent souvent des exemples concrets lors des revues de schéma, parce que rien ne remplace un petit cas réel pour détecter un angle mort. Ce temps investi s’amortit dès la première campagne agitée.
Front‑end et accessibilité au service de la confiance
Une interface claire rend la technique crédible. L’accessibilité et la sobriété désamorcent les malentendus. Les spécialistes préconisent des formulaires explicites, des résumés de conditions lisibles et des états bien synchronisés avec les décisions réelles côté serveur. La cohérence des messages, surtout en cas de refus, compte davantage que la vitesse brute pour l’acceptation par le public. Entre autres, les états de chargement et les files visibles évitent la tentation de cliquer frénétiquement, ce qui protège également l’infrastructure. D’ailleurs, des textes d’aide rédigés par l’équipe technique elle‑même gagnent du temps au support, car ils reflètent les mécanismes réels plutôt qu’un brouillard marketing.
Sur le plan technique, les composants critiques doivent fonctionner même en cas de lenteur réseau : choix d’interactions tolérantes aux délais, reconduction prudente des tentatives, et affichage local des confirmations tout en s’appuyant sur la décision finale côté serveur. Les collègues insistent pour que les boutons d’action ne puissent pas déclencher plusieurs requêtes concurrentes sans jeton valable, ce qui évite la nébuleuse des « doubles ». Un soin particulier sur la pagination et les historiques visibles apaise les esprits et évite des sollicitations inutiles du support.
L’accessibilité n’est pas un supplément, c’est une démonstration de sérieux. Des contrastes suffisants, des commandes au clavier, des étiquettes claires et des annonces prononcées par les lecteurs d’écran renforcent la confiance de tous, y compris de ceux qui ne s’en servent pas au quotidien. En filigrane, cette rigueur rejaillit sur la perception du programme d’avantages, comme si une bonne typographie consolait l’œil pendant que la pile technique travaille.
Pour mémoire, une liste de vérification frontale utile avant une grande mise en avant :
- Boutons protégés contre les envois multiples non idempotents
- Messages d’erreur précis, courts et actionnables pour l’utilisateur
- États de chargement et file visible en cas de pic de trafic
- Résumé clair des conditions et des limites temporelles
- Compatibilité clavier et lecteurs d’écran vérifiée
- Comportement stable en cas de lenteur ou perte momentanée
- Synchronisation stricte avec l’état serveur pour les confirmations
- Journal technique côté navigateur limité et respectueux de la vie privée
Gouvernance, conformité et audit technique
Un service d’avantages inspire confiance quand sa gouvernance est lisible. Les règles sont versionnées, signées, et leur diffusion contrôlée. Les spécialistes recommandent d’écrire les politiques comme des documents vivants, avec motifs, impacts attendus et exemples, puis de les attacher aux versions déployées pour que chaque décision puisse être expliquée. Le règlement général sur la protection des données guide la collecte minimale et l’information claire de l’utilisateur, de préférence avant que l’enthousiasme n’emporte tout. Entre autres, la possibilité pour un usager d’accéder à l’historique de ses décisions, proprement anonymisé côté support, réduit les cris dans les boîtes de réception.
L’audit technique s’appuie sur des journaux immuables et signés, stockés séparément de la base opérationnelle, avec un accès restreint et tracé. Les collègues aiment employer des mécanismes de hachage en chaîne pour détecter toute altération, et, honnêtement, ce n’est pas tant pour se protéger d’un loup interne que pour se préparer au jour où l’on devra reconstituer un incident sans débat. Une procédure d’exercice régulier — simulation d’incident, restitution devant un pair — maintient la vivacité des réflexes. Ce rituel n’empêche pas les erreurs, mais amenuise leurs conséquences.
Enfin, la communication externe en période de tension compte presque autant que la correction technique. Un message franc, des délais réalistes, un canal dédié et la reconnaissance des frustrations calment la houle. Les équipes IT, souvent invisibles, y trouvent aussi une reconnaissance méritée, tant leur travail silencieux a permis que l’orage n’emporte pas tout. Curieusement, c’est dans ces moments‑là que se construit la réputation la plus solide.
Checklist de mise en production et erreurs fréquentes
Une bonne mise en production commence par un rituel simple et ferme. Les pièges récurrents se désamorcent en amont. Les spécialistes ont rassemblé ci‑dessous une liste éprouvée, qui croise réseau, application et support pour couvrir l’essentiel sans débats interminables. Selon l’expérience des collègues, cocher ces éléments prend peu de temps et évite l’essentiel des quiproquos et des réveils tardifs. Entre autres, elle alimente la documentation vivante du projet et la mémoire de l’équipe. Et, honnêtement, le plaisir de répondre « oui » à chaque ligne vaut bien quelques heures de préparation.
- Horloge disciplinée sur tous les nœuds, écarts surveillés et test canari actif
- Règles d’offre versionnées, signées, consultables et reliées au déploiement
- Mise en cache du catalogue contrôlée, invalidation et réchauffage testés
- Limitation de débit configurée et scénarios de dégradation prêts
- Opérations idempotentes pour l’attribution, clés naturelles en place
- Journalisation d’audit immuable et corrélation par identifiant de décision
- Alertes claires sur latence, refus, erreurs d’écriture, épaisseur de file
- Page de transparence publique sur les critères généraux d’éligibilité
Les erreurs fréquentes se ressemblent tristement : durée de vie des caches trop longue lors d’un changement d’adresse ; certificat oublié sur un sous‑domaine ; règle métier modifiée sans version ; horloge d’un nœud en roue libre ; formulaire autorisant plusieurs envois concurrents ; file de messages sans zone de quarantaine ; absence d’outil de relecture des décisions. Pour chacune, le correctif durable s’écrit dans la procédure, pas seulement dans le code. D’ailleurs, un retour d’expérience obligeant à montrer comment l’erreur ne peut plus se reproduire vaut plus que mille excuses.
Pour approfondir certains de ces points techniques, le lecteur trouvera utile la section sur le protocole de temps réseau, l’article détaillé sur le système de noms de domaine et le guide du mandataire inverse. Ces ressources, ancrées dans la pratique quotidienne, complètent la présente synthèse sans la surcharger. Elles servent, entre autres, de base aux formations internes lors des renouvellements d’équipe.
Conclusion: l’art de la précision au service de la confiance
Au bout du compte, un programme d’avantages n’est qu’un miroir tendu à l’infrastructure qui le supporte. La scène commerciale attire l’œil, mais c’est la coulisse réseau, la discipline de l’horloge, la sobriété de la base et la rigueur des journaux qui soutiennent la pièce. Les spécialistes notent que l’exemple du lien vers un casino bonus sans depot sert moins à vanter qu’à illustrer la pression concrète qu’exercent des foules enthousiastes sur des mécanismes sensibles. Quand ces mécanismes sont sobres, explicables et mesurés, la confiance grandit, et l’équipe dort enfin.
Ce texte a voulu relier l’ingénierie réseau, la conception d’applications et l’administration de systèmes à une situation très concrète, presque prosaïque, mais riche en enseignements. Entre la pulsation d’une horloge synchronisée et la douceur d’un message d’erreur bien rédigé, se tisse l’expérience que chacun retient. Les collègues aiment conclure ainsi : l’architecture qui tient dans les nuits agitées est celle qui, déjà, savait raconter son histoire en plein jour.